오늘도 Azure로운 Power Platform :D
요새 새로이 등장하고 있는 데이터 아키텍처가 있습니다. ELTL이죠.
Extract - Load - Transform - Load
순서로 구성된 아키텍처입니다. 기존의 ETL이나 ELT 방식의 끝에 로드단계가 하나 더 붙었습니다.
ELTL구조로 데이터 아키텍처를 간단히 그려본다면 다음과 같을 겁니다.
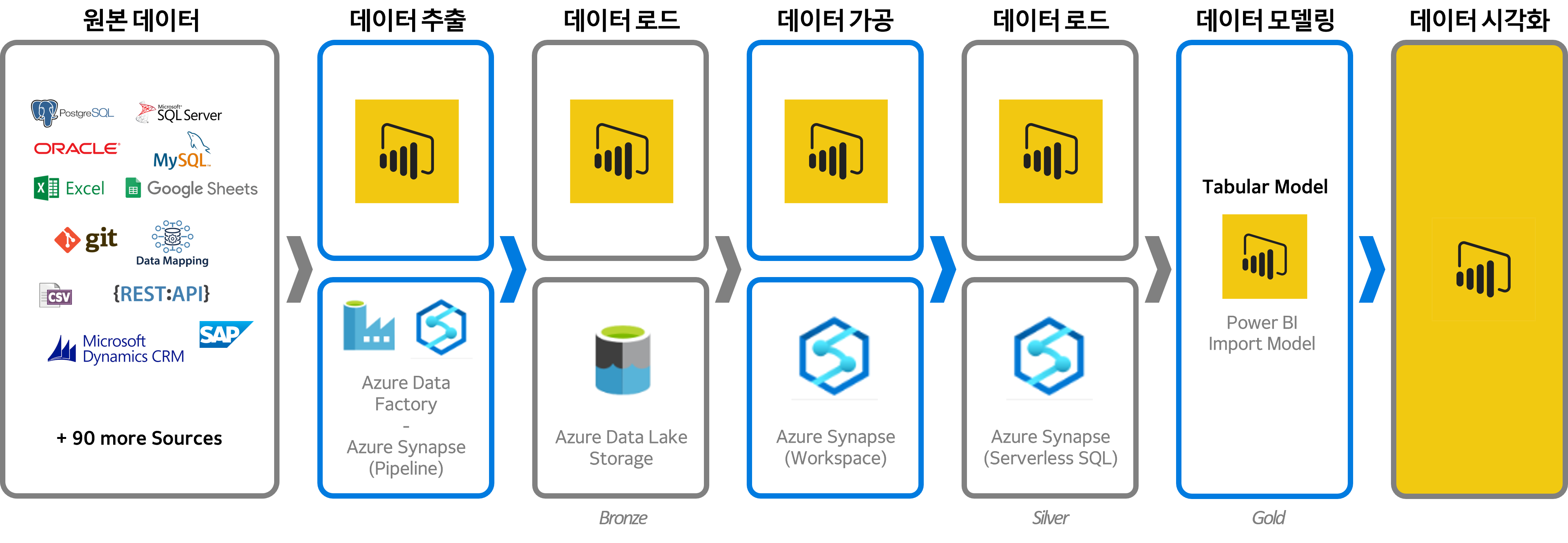
우선 위 그림을 간단히 설명하자면, 추출부터 마지막 로드까지를 오직 Power BI로만 처리한 방법과 Azure를 사용한 방법으로 나뉩니다. 구분 기분은 구축 규모죠. Power BI로만 구성된 흐름은 Self BI에 적합하며, Azure를 사용한 흐름은 엔터프라이즈 규모에 적합합니다.
(간혹 Power BI로 아예 안되는 것은 아니지 않느냐 하시는 분들이 계신데 그럴 경우엔 속도는 포기해주시길 부탁드립니다..)
그림 맨 하단에 Bronze, Silver, Gold 라고 쓰여있는데 이 용어들은 데이터의 상태를 나태내는 용어입니다.
[Bronze]
원본에서 그대로 가져온 raw 데이터 상태를 의미합니다.
[Silver]
가공이 완료된 데이터를 의미합니다.
[Gold]
모델링까지 완료된 cube형태의 데이터를 의미합니다.
위 구성이 등장하게된 배경에는 다양한 원인들이 있지만 현실적인 원인을 하나 뽑자면 머신러닝과 인공지능 분석의 등장이 아닐까 합니다. 즉, 분석 단계의 등장이죠.
그동안 ETL과 ELT 방식을 데이터를 관리해왔지만 이제는 ELTL을 지향하는 추세입니다.
ETL은 실시간 데이터 처리가 힘들고 raw 데이터 보관이 안되는 등의 이유들로 현재는 ELT를 많이 사용하고 있습니다. 그러나 이제는 가공된 데이터를 다시 저장 및 관리할 필요성이 생기기 시작했죠.
데이터 분석(Analysis) 단계의 등장
가공된 데이터를 사용하여 보고서를 산출하거나 인사이트 발견을 위해서만 사용하는 시기는 지났습니다. 이제는 가공된 데이터를 활용하여 컴퓨터로 분석하여 사람이 발견하지 못하는 인사이트를 발견하고 그 인사이트를 문제해결에 활용하는 세상을 우리는 살고 있습니다.
머신러닝을 돌리기 위해서는 가공된 데이터를 사용해야 합니다. 인공지능 분석도 마찬가지입니다. 그러나 ELT를 사용하고 있는 환경에서는 가공된 데이터가 제대로 보관되거나 관리되지 못합니다. 만일 머신러닝을 돌리고자 한다면 raw 데이터를 끌고과 가공하는 것부터 다시 해야합니다.
혹은 다른 머신러닝 모델로 데이터를 다시 돌려보고자 한다면, raw 데이터를 가져와 동일한 형태로 가공하는 작업을 반복해야합니다. 같은 일을 여러번 하게 되는 것이죠.
이제는 가공한 데이터를 바로 엔드 포인트로 끌어와 사용하는 것이 아니라 다음단계인 분석을 위해 사용될 수도 있기 때문에 그 데이터를 보관하고 관리해야합니다. 이 때의 데이터는 Silver 테이블이 됩니다.
데이터 재사용

데이터 관련 프로젝트시 데이터의 재사용은 반드시 고려되어야 하는 개념입니다. 한번 구축된 데이터 아키텍처 및 로드/가공된 데이터는 앞으로 계속 사용될겁니다. 즉, 확장성을 염두해야 하죠.
이때 ELTL 구조로 구축했다면, 이후 데이터 분석 프로젝트나 시각화 프로젝트 등 어떤 프로젝트를 하게되더라도 데이터를 원본에서 부터 가져와 가공하는 것이 아니라 가공되어 있는 데이터를 바로 가져오면 되니 그만큼의 리소스도 절약됩니다.
데이터는 보통 트랜젝션 단위로 비용이 청구 됩니다. 트랜젝션 시 걸린 시간보다는 양에 초점을 맞춰서 생각해야합니다. 아키텍처 처음부터 다시 돌리는 것보다 저장되어 있는 데이터를 바로 끌어다 사용하는 편이 리소스 절약면에서 훨 낫습니다. 데이터를 가져오는 속도도 빨라지죠.
Back track / 유지보수 및 관리 / 에러 대응
데이터를 중간중간 로드하는 단계를 구축해 놓으면 관리 측면에서도 효율적입니다. 문제나 에러가 생겼을 때 그 원인을 back track 하기에도 수월하고 편리하죠.
또한 에러 발생시 에러 사항이 엔드 포인트까지 넘어가지 않아 실제 서비스에는 영향을 미치지 않습니다.
과거에는 모아둔 데이터를 가공하여 인사이트를 얻었다면, 이제는 가공한 데이터를 컴퓨터로 분석하여 문제해결을 위해 사용합니다. DT를 생각하시는 분들은 ELTL을 생각해보시길 바랍니다. 특히 차후 데이터 분석 프로젝트를 고려하고 있다면 더더욱 말이죠.
'Big Data > 데이터 기초' 카테고리의 다른 글
| ETL과 ELT (데이터 프로세싱 아키텍처/가공 처리 과정) (0) | 2022.08.03 |
|---|---|
| 빅데이터랑 4차 산업혁명 (0) | 2022.07.08 |
| 데이터 가치 (0) | 2022.07.07 |



댓글