오늘도 Azure로운 Power Platform :D
지난 clustering에 이은 logistic regression 머신러닝 포스팅입니다.
(Power BI에서 Python script를 사용하는 방법은 아래 포스팅을 참고해주시기 바랍니다.)
https://azureplatform.tistory.com/20
[Power BI] 머신러닝 I - Clustering (Pro 라이선스/Python 스크립트)
오늘도 Azure로운 Power Platform :D Power BI는 Premium 라이선스부터 머신러닝을 사용할 수 있다고 알려져 있죠. 이는 코딩을 모르시는 분들께는 맞는 설명이나, 약간의 코딩이라도 하실 줄 안다면 얘기
azureplatform.tistory.com
Supervised learning 모델 중 하나인 Logistic Regression은 보통 특정 사건이 발생할 확률을 예측합니다. 수식은 다음과 같습니다.
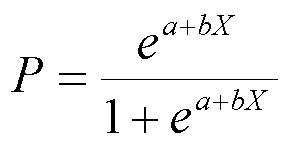
이번 포스팅에서 사용할 데이터셋은 통신사 회사의 샘플데이터로, 이탈고객을 예측하려고 합니다.
| 변수 명 | 내용 | 구분 |
| COLLEGE | 대학졸업 여부(1,0) | |
| INCOME | 연 수입액(달러) | |
| OVERAGE | 월 초과사용 시간(분) | |
| LEFTOVER | 월 사용 잔여시간비율(%) | |
| HOUSE | 집 가격(달러) | |
| HANDSET_PRICE | 핸드폰 가격(달러) | |
| OVER_15MINS_CALLS_PER_MONTH | 평균 장기통화(15분 이상) 횟수 | |
| AVERAGE_CALL_DURATION | 평균 통화시간(분) | |
| REPORTED_SATISFACTION | 만족도 설문('very_unsat', 'unsat', 'avg', 'sat', 'very_sat' ) | |
| REPORTED_USAGE_LEVEL | 사용 수준 설문('very_little', 'little', 'avg', 'high', 'very_high') | |
| CONSIDERING_CHANGE_OF_PLAN | 변경 계획 설문('never_thought', 'no', 'perhaps', 'considering', 'actively_looking_into_it') | |
| CHURN | 이탈여부(1 : 이탈, 0 : 잔류) | Target |
1. 데이터 로드 및 머신러닝 분석
데이터를 로드한 후 python script로 가공합니다. Power query 편집기 창에서 Transform탭의 python script를 엽니다.


전체 코드는 아래와 같습니다.
# 'dataset' holds the input data for this script
#Load in the dependencies
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import MinMaxScaler
mobile = dataset
target = 'CHURN'
x = mobile.drop(target, axis=1)
y = mobile.loc[:,target]
mean_HOUSE = x['HOUSE'].mean()
x['HOUSE'].fillna(mean_HOUSE, inplace=True)
x['REPORTED_SATISFACTION'].fillna('avg', inplace =True)
cat_col = ['REPORTED_SATISFACTION','REPORTED_USAGE_LEVEL','CONSIDERING_CHANGE_OF_PLAN']
x = pd.get_dummies(x,columns=cat_col, drop_first=True)
x_train_val, x_test, y_train_val, y_test = train_test_split(x,y,test_size=2000)
x_train, x_val, y_train, y_val = train_test_split(x_train_val,y_train_val,test_size=2000)
scaler = MinMaxScaler()
x_train_s = scaler.fit_transform(x_train)
x_val_s = scaler.transform(x_val)
x_test_s = scaler.transform(x_test)
x_s = scaler.transform(x)
model_lr = LogisticRegression()
model_lr.fit(x_train_s,y_train)
pred_lr = model_lr.predict(x_s)
# Lets add the columns back to the dataframe
dataset['predictions'] = pred_lr
2. 시각화 비교
다음은 머신러닝을 돌려 나온 예측값과 실제값을 비교한 그래프입니다
.



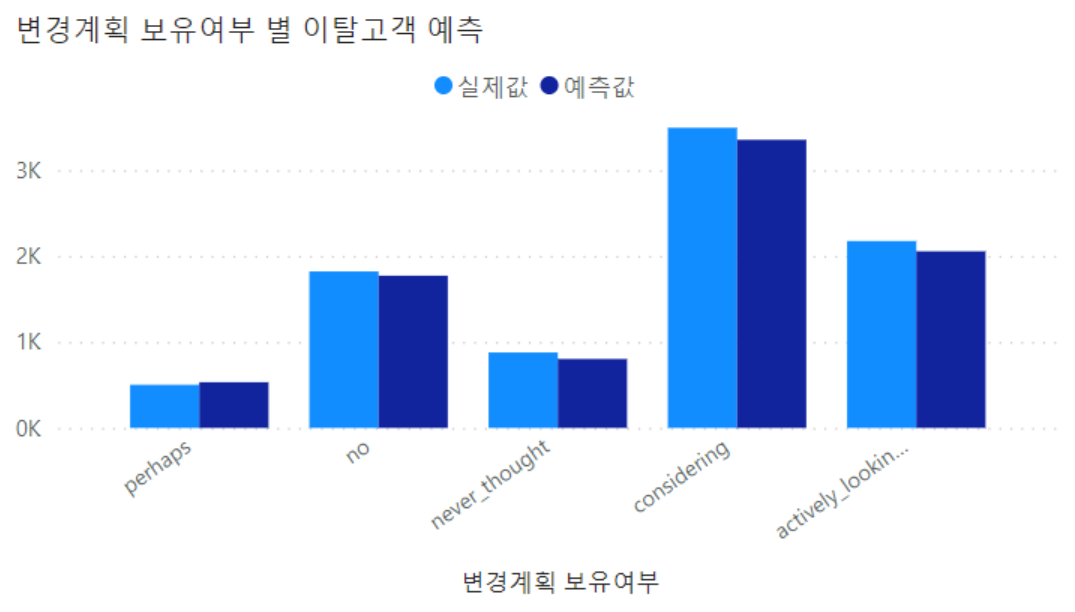
Logistic Regression을 간단하게 분석해보았습니다. 다른 모델을 사용하거나, 앙상블이나 튜닝 등의 방법을 통해 오차를 줄여봐도 좋을 듯 합니다.
Power BI를 어떻게 응용하면 좋을지 아이디어를 떠올리시는데 조금이라도 도움이 되었길 바랍니다. :)
'Azure로운 Power Platform > Power Platform' 카테고리의 다른 글
| [Power BI] 임베디드 라이선스 (Power BI Embedded Analytics) (0) | 2022.08.23 |
|---|---|
| [Power BI] 동적 데이터 라벨 (Dynamic Data Label/Tabular Editor) (0) | 2022.08.18 |
| [Power BI] 머신러닝 I - Clustering (Pro 라이선스/Python 스크립트) (0) | 2022.08.08 |
| [Power BI] 필드명으로 슬라이서 만들기 (Field Parameter/Field Slicer) (0) | 2022.08.01 |
| [Power BI] PBI와 PBIE 비교 (Power BI vs. Power BI Embedded) (1) | 2022.07.30 |



댓글